Case Study: Intelligent Knowledge Orchestration for a Leading Global Financial Institution
Key Impact
Faster Knowledge Access: Document retrieval times reduced from hours to seconds, with average query response under 4 seconds across the full document corpus
Improved Accuracy: Generated summaries validated through random sampling audits and continuous offline evaluation against compliance-approved golden datasets
Reusable Architecture: A governed, extensible foundation now deployed across additional knowledge domains within the bank including treasury, trade finance, and customer onboarding
Reduced compliance and conduct risk by eliminating answer inconsistency that had been flagged as a material control gap by internal audit
Challenge
Solution
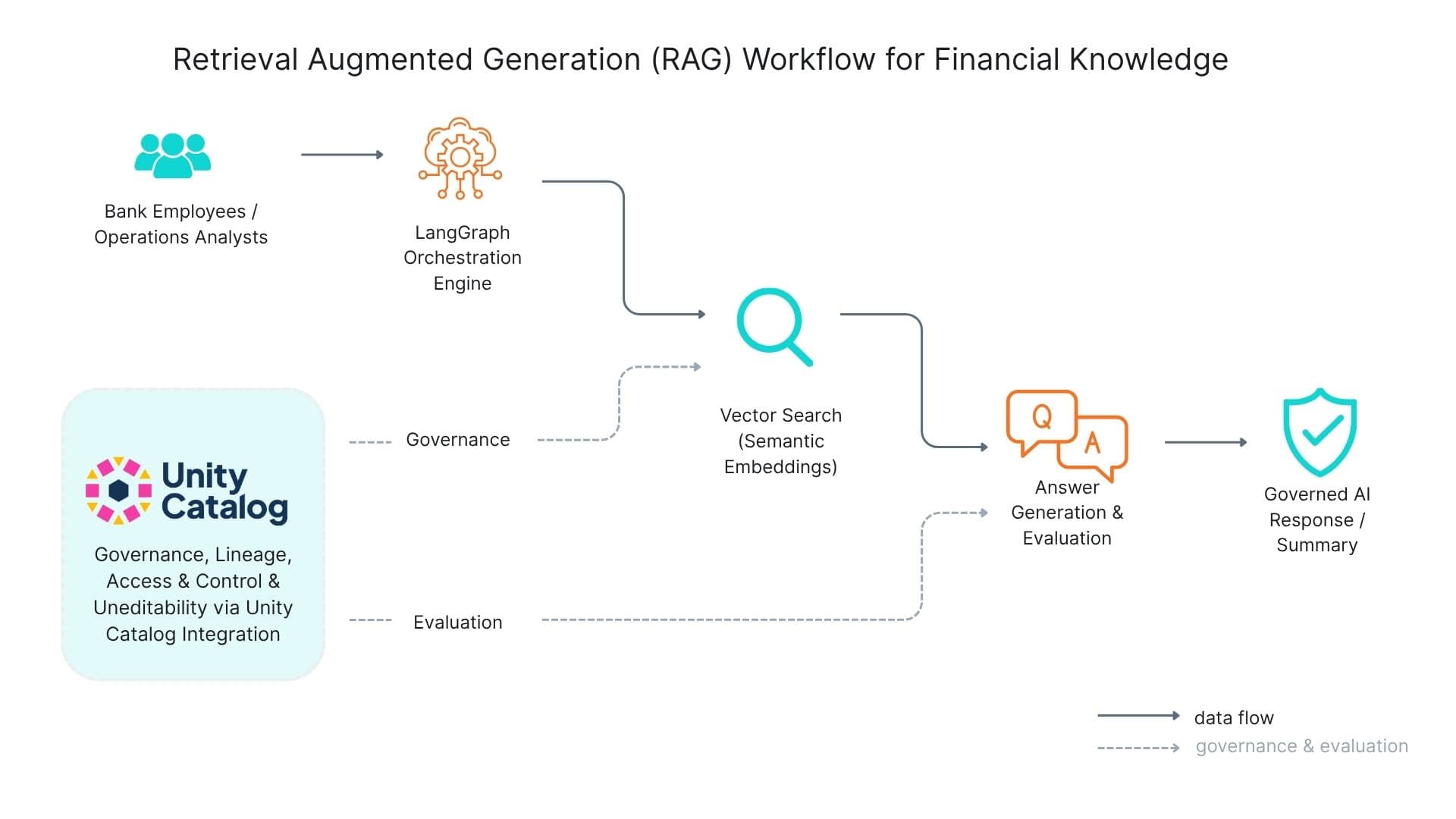
Retrieval Augmented Generation (RAG) Workflow Architecture showing data flow, governance, and evaluation processes
Technology Stack
Ready for Similar Results?
Let's discuss how we can help transform your organisation's data and AI capabilities.